awesome-mojo
Awesome Mojo🔥

Mojo 🔥 — a new programming language for all developers, AI/ML scientists and software engineers.
A curated list of awesome Mojo🔥 code, problem-solving, solution, and in future libraries, frameworks, software and resources.
Let’s accumulate here very new technology knowledge and best practices.
Mojo is a programming language that combines the user-friendliness of Python with the performance capabilities of C++ and Rust. Additionally, Mojo enables users to harness the vast ecosystem of Python libraries.
In a brief
- Mojo allows you to leverage the entire Python ecosystem.
- Mojo is designed to become a superset of Python.
- Make Mojo compatible with existing Python programs.
- Mojo as a member of the Python family.
- Applied for AI systems and AI field.
- Scalable programming for heterogeneous systems.
- Building unify the world’s ML/AI infrastructure.
- Innovations in compiler internals.
- Support for current and emerging hardware accelerators.
- Systems programming features.
- Leverage the existing MLIR compiler ecosystem.
Hello Mojo🔥
Mojo is a new programming language that bridges the gap between research and production by combining the best of Python syntax with systems programming and metaprogramming.
hello.mojo or hello.🔥 the file extension can be an emoji!
You can read more about why Modular doing this Why Mojo🔥
What we wanted was an innovative and scalable programming model that could target accelerators and other heterogeneous systems that are pervasive in the AI field. … Applied AI systems need to address all these issues, and we decided there was no reason it couldn’t be done with just one language. Thus, Mojo was born.
But Python has done its job very well =)
We didn’t see any need to innovate in language syntax or community. So we chose to embrace the Python ecosystem because it is so widely used, it is loved by the AI ecosystem, and because we believe it is a really nice language.
Why is it called Mojo?
Mojo🔥 means “a magical charm” or “magical powers.” We thought this was a fitting name for a language that brings magical powers to Python :python:, including unlocking an innovative programming model for accelerators and other heterogeneous systems pervasive in AI today.
Guido van Rossum benevolent dictator for life and Christopher Arthur Lattner distinguished inventor, creator and well-known leader about Mojo🔥pronunciation =)
According to the description
Background and influenced by
Who knows that these programming languages will be very happy, because Mojo benefits from tremendous lessons learned from other languages Rust, Swift, Julia, Zig, Nim, etc.
- Rust starts the C revolution and now Rust in the Linux kernel.
- Swift makes Apple beautiful from a technical perspective.
- Julia high performance.
- Nim systems programming language.
- Zig general-purpose programming language. We are like and following it =)
News
[new]
-
Github now auto-detects Mojo code 🔥!
- Simple and fast HTTP framework for Mojo! 🔥 Perfect for building web services and simple APIs. For Mojicians
- LLama implementations benchmarking framework
- Automated Python to Mojo code translation
- Programming Language DataBase Research
- October 19, 2023 Mojo🔥 is now available on Mac! Use developer console
-
[Chris Lattner: Future of Programming and AI Lex Fridman Podcast #381](https://www.youtube.com/watch?v=pdJQ8iVTwj8) -
[Mojo and Python type system explained Chris Lattner and Lex Fridman](https://www.youtube.com/watch?v=0VCq8jJjAPc) -
[Can Mojo run Python code? Chris Lattner and Lex Fridman](https://www.youtube.com/watch?v=99hRAvk3wIk) -
[Switching from Python to Mojo programming language Chris Lattner and Lex Fridman](https://www.youtube.com/watch?v=7wo4vyB7l3s) -
New GitHub Topic mojo-lang. So you can follow it.
- Guido van Rossum about Mojo = Python with C++/GPU performance?

- Tensor struct with some basic ops #251
- Matrix fn with numpy #267
- Updates about
lambdaandparameterClosures and higer order functions in mojo #244 - May-25-2023, Guido van Rossum (gvanrossum#8415), creator and emeritus BDFL of Python, visit the Mojo🔥 public Discord Chat
- Waiting for a Mojo🔥 syntax highlighting at GitHub
- New Mojo🔥release 2023-05-24
[old]
Mojo🔥
Benchmarks
Tools
- hyperfine a command-line benchmarking tool
brew install hyperfine
- macchina a system information frontend with an emphasis on performance.
brew install macchina
- Python3 libs for plots
pip3 install numpy matplotlib scipy
- Code to image PNG
brew install silicon
Benchmarking environment
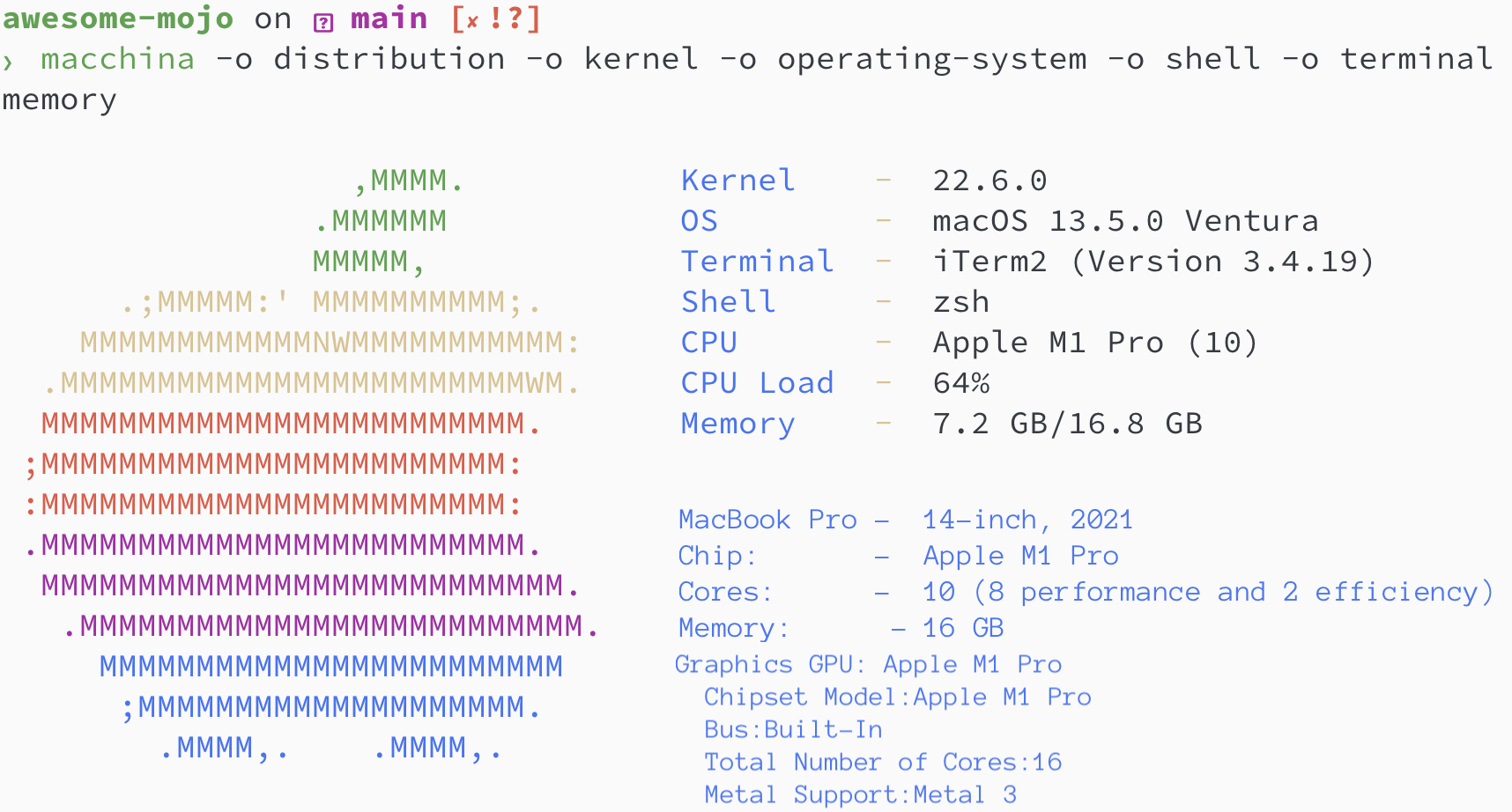
Python / Mojo / Codon / Rust versions
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)
Fibonacci Sequence
Lets find Fibonacci Sequence where
N = 100
Python Fibonacci Sequence Recursion
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json 'python3 benchmarks/fibonacci_sequence/python_recursion.py'
RESULT: TIMEOUT, I canceled computation after 1m
Python Fibonacci Sequence Iteration
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json 'python3 benchmarks/fibonacci_sequence/python_iteration.py'
RESULT:
Benchmark 1: python3 benchmarks/fibonacci_sequence/python_iteration.py
Time (mean ± σ): 16374.7 µs ± 904.0 µs [User: 11483.5 µs, System: 3680.0 µs]
Range (min … max): 15361.0 µs … 22863.3 µs 100 runs
Compile Python byte code
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.py
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json 'python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc'
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json 'python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc'
RESULT:
Benchmark 1: python3 benchmarks/fibonacci_sequence/pycache/python_iteration.cpython-311.pyc
Time (mean ± σ): 16584.6 µs ± 761.5 µs [User: 11451.8 µs, System: 3813.3 µs]
Range (min … max): 15592.0 µs … 20953.2 µs 100 runs
Mojo Fibonacci Sequence Recursion
fn fibonacci_recursion(n: Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fn main():
_ = fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json 'mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo'
RESULT: TIMEOUT, I canceled computation after 1m
Mojo Fibonacci Sequence Iteration
fn fibonacci_iteration(n: Int) -> Int:
var a: Int = 0
var b: Int = 1
for _ in range(n):
a = b
b = a+b
return a
fn main():
_ = fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json 'mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo'
RESULT:
Benchmark 1: mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo
Time (mean ± σ): 43852.7 µs ± 1353.5 µs [User: 38156.0 µs, System: 10407.3 µs]
Range (min … max): 42033.6 µs … 49357.3 µs 100 runs
Compile Mojo code
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojo
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json './benchmarks/fibonacci_sequence/mojo_recursion'
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json './benchmarks/fibonacci_sequence/mojo_iteration'
RESULT:
Benchmark 1: ./benchmarks/fibonacci_sequence/mojo_iteration
Time (mean ± σ): 934.6 µs ± 468.9 µs [User: 409.8 µs, System: 247.8 µs]
Range (min … max): 552.7 µs … 4522.9 µs 100 runs
Codon Fibonacci Sequence Recursion
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json 'codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon'
RESULT: TIMEOUT, I canceled computation after 1m
Codon Fibonacci Sequence Iteration
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json 'codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon'
RESULT:
Benchmark 1: codon run –release benchmarks/fibonacci_sequence/codon_iteration.codon
Time (mean ± σ): 628060.1 µs ± 10430.5 µs [User: 584524.3 µs, System: 39358.5 µs]
Range (min … max): 612742.5 µs … 662716.9 µs 100 runs
Compile Codon code
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codon
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json './benchmarks/fibonacci_sequence/codon_recursion'
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json './benchmarks/fibonacci_sequence/codon_iteration'
RESULT:
Benchmark 1: ./benchmarks/fibonacci_sequence/codon_iteration
Time (mean ± σ): 2732.7 µs ± 1145.5 µs [User: 1466.0 µs, System: 1061.5 µs]
Range (min … max): 2036.6 µs … 13236.3 µs 100 runs
Rust Fibonacci Sequence Recursion
fn fibonacci_recursive(n: i64) -> i64 {
if n < 2 {
return n;
}
return fibonacci_recursive(n - 1) + fibonacci_recursive( n - 2);
}
fn main() {
let _ = fibonacci_recursive(100);
}
rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json './benchmarks/fibonacci_sequence/rust_recursion'
RESULT: TIMEOUT, I canceled computation after 1m
Rust Fibonacci Sequence Iteration
fn fibonacci_iteration(n: usize) -> usize {
let mut a = 1;
let mut b = 1;
for _ in 1..n {
let old = a;
a = b;
b += old;
}
b
}
fn main() {
let _ = fibonacci_iteration(100);
}
rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json './benchmarks/fibonacci_sequence/rust_iteration'
RESULT:
Benchmark 1: ./benchmarks/fibonacci_sequence/rust_iteration
Time (mean ± σ): 848.9 µs ± 283.2 µs [User: 371.8 µs, System: 261.4 µs]
Range (min … max): 525.9 µs … 2607.3 µs 100 runs
Summary Fibonacci Sequence
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.png
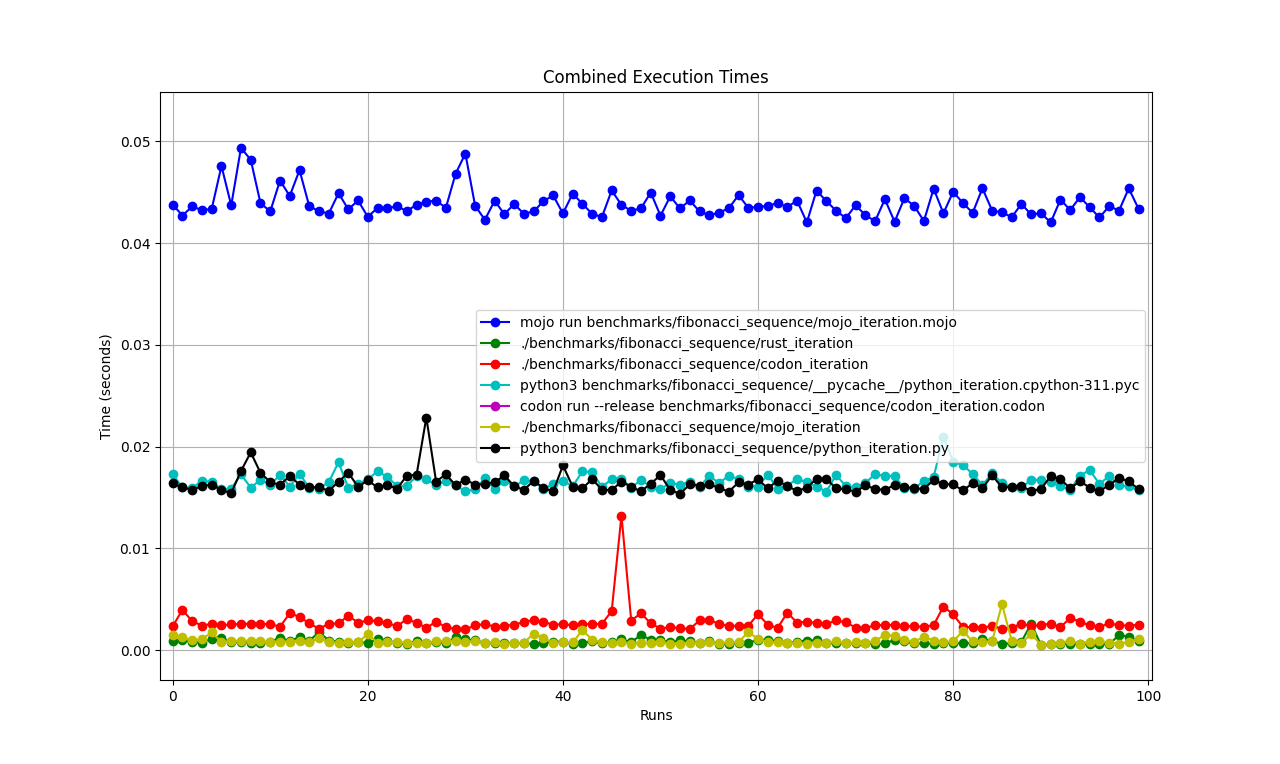
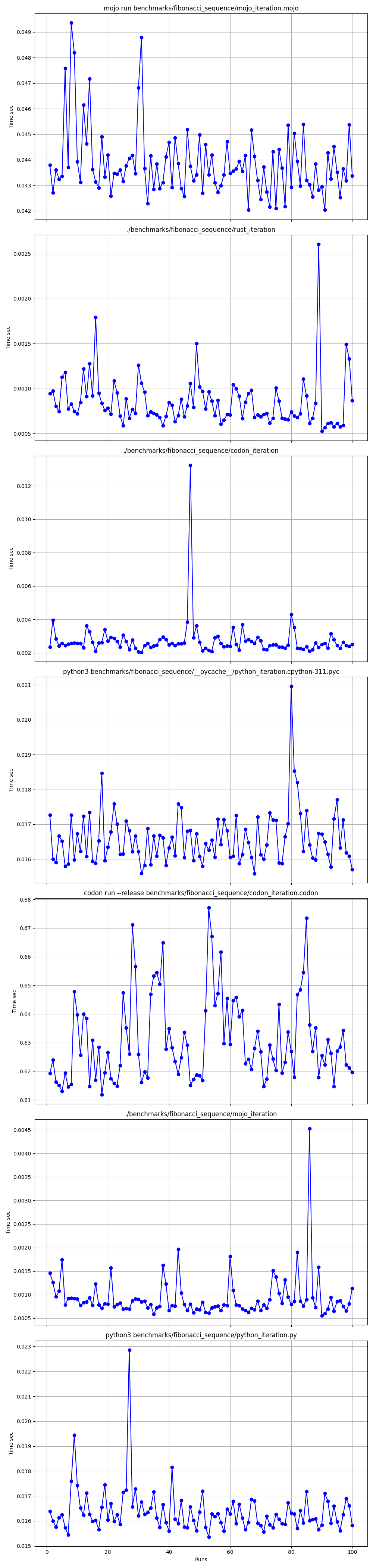
Advanced statistics
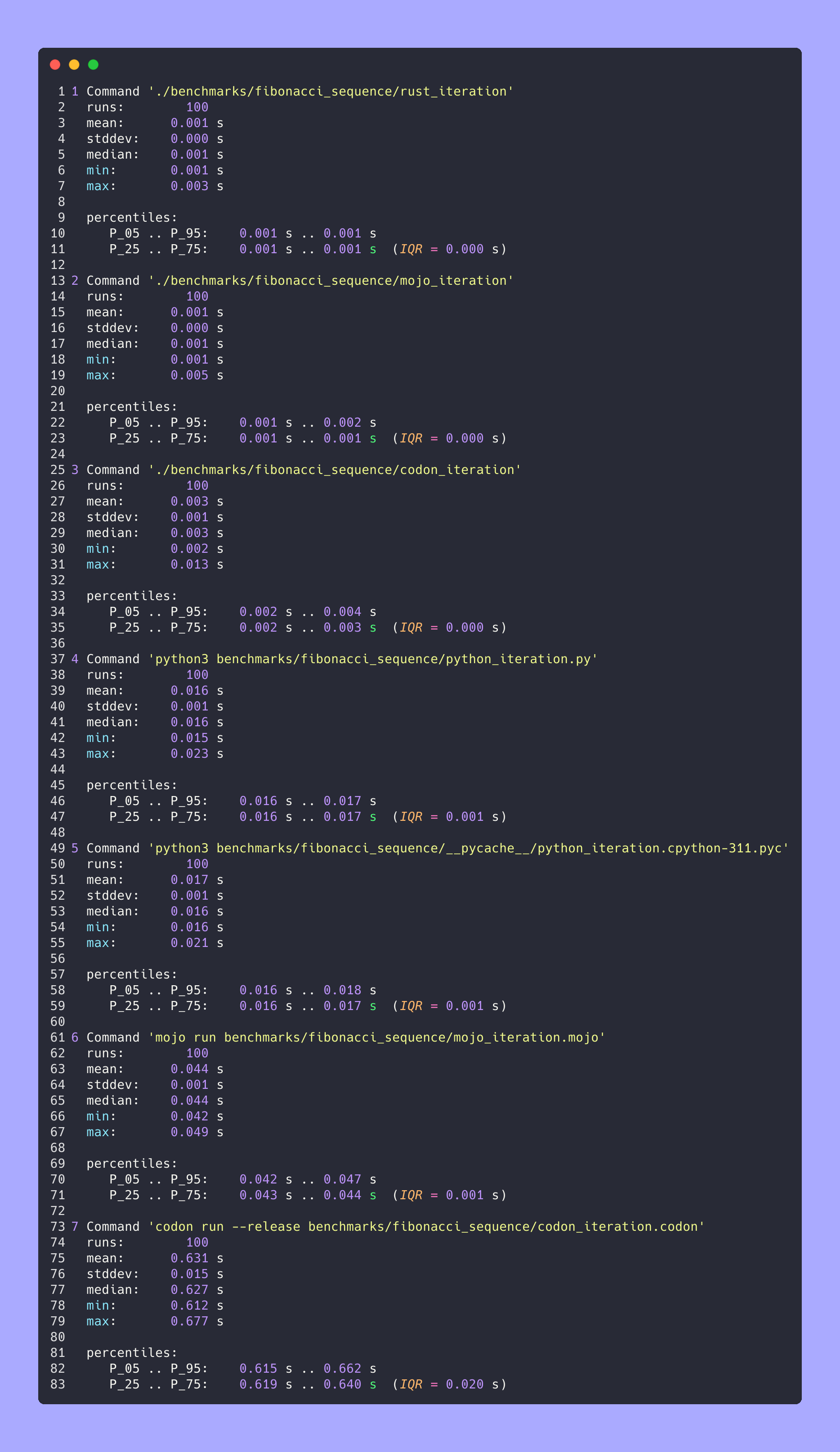
All together
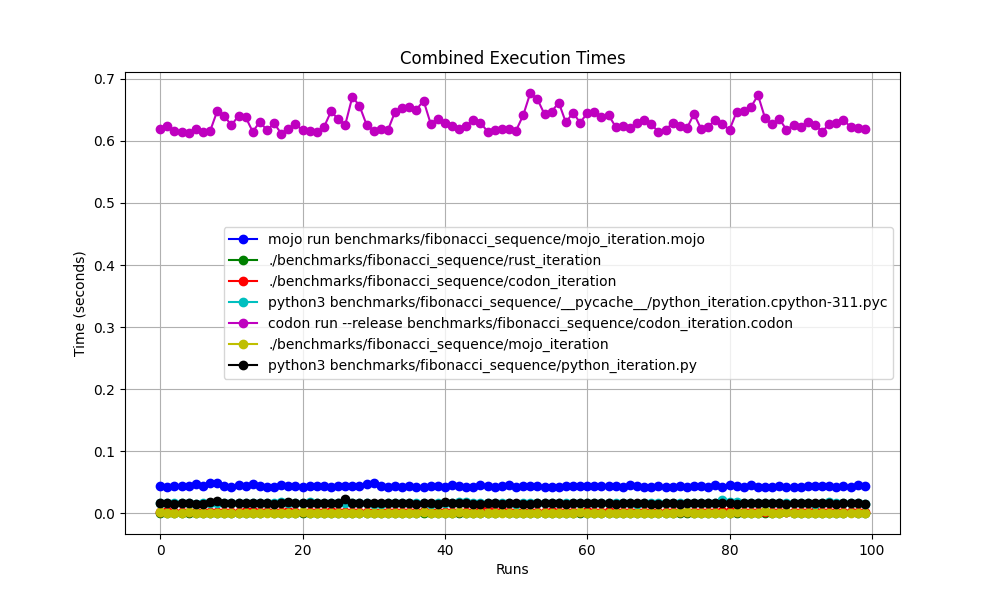
Zoomed
Detailed one by one
Places
- Rust
- Mojo
- Codon
- Python
But here a lot of questions:
- How to optimize code/build/run?
- Why
mojo runso slow? - Why
codon run --releaseso slow? - Why compiled Python byte code +/- equals Python interpreter?
- Why Python interpreter faster than Mojo/Codon
run?
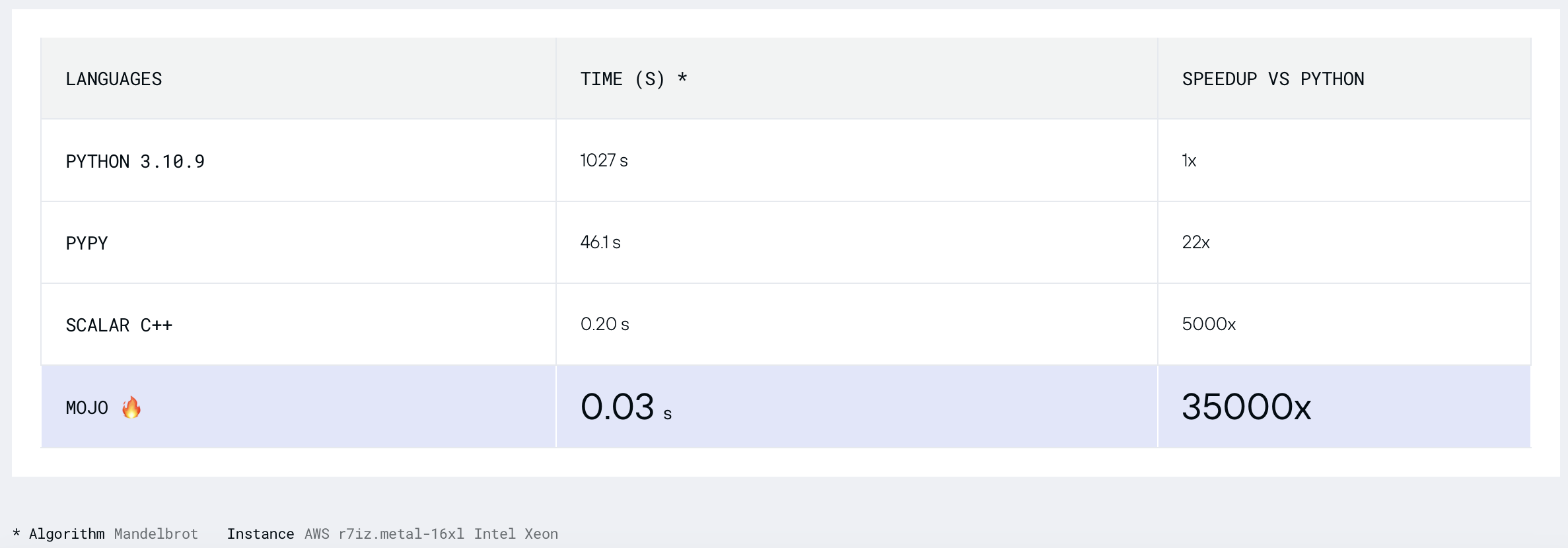
So, we can say that Mojo🔥 is as fast as Rust on Mac!
Mandelbrot Set
Lets find Mandelbrot Set where
WIDTH = 960
HEIGHT = 960
MAX_ITERS = 200
MIN_X = -2.0
MAX_X = 0.6
MIN_Y = -1.5
MAX_Y = 1.5
Python Mandelbrot Set
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
python3 -m compileall benchmarks/multibrot_set/multibrot.py
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json 'python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc'
RESULT:
Benchmark 1: python3 benchmarks/multibrot_set/pycache/multibrot.cpython-311.pyc
Time (mean ± σ): 5444155.4 µs ± 23059.7 µs [User: 5419790.1 µs, System: 18131.3 µs]
Range (min … max): 5408155.3 µs … 5490548.4 µs 10 runs\
Mojo Mandelbrot Set
Mojo version with no optimization.
# Compute the number of steps to escape.
def multibrot_kernel(c: ComplexFloat64) -> Int:
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4:
return i
return MAX_ITERS
def compute_multibrot() -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType](HEIGHT, WIDTH)
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
y = MIN_Y
for row in range(HEIGHT):
x = MIN_X
for col in range(WIDTH):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()
mojo build benchmarks/multibrot_set/multibrot.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json './benchmarks/multibrot_set/multibrot'
RESULT:
Benchmark 1: ./benchmarks/multibrot_set/multibrot
Time (mean ± σ): 135880.5 µs ± 1175.4 µs [User: 133309.3 µs, System: 1700.1 µs]
Range (min … max): 134639.9 µs … 137621.4 µs 10 runs
Mojo Parallelized Mandelbrot Set
fn mandelbrot_kernel_SIMD[
simd_width: Int
](c: ComplexSIMD[float_type, simd_width]) -> SIMD[float_type, simd_width]:
"""A vectorized implementation of the inner mandelbrot computation."""
let cx = c.re
let cy = c.im
var x = SIMD[float_type, simd_width](0)
var y = SIMD[float_type, simd_width](0)
var y2 = SIMD[float_type, simd_width](0)
var iters = SIMD[float_type, simd_width](0)
var t: SIMD[DType.bool, simd_width] = True
for i in range(MAX_ITERS):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1, iters)
return iters
fn compute_multibrot_parallelized() -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker(row: Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector[simd_width: Int](col: Int):
"""Each time we operate on a `simd_width` vector of pixels."""
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main():
_ = compute_multibrot_parallelized()
mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json './benchmarks/multibrot_set/multibrot_mojo_parallelize'
RESULT:
Benchmark 1: ./benchmarks/multibrot_set/multibrot_mojo_parallelize
Time (mean ± σ): 7139.4 µs ± 596.4 µs [User: 36535.2 µs, System: 6670.1 µs]
Range (min … max): 6222.6 µs … 8269.7 µs 10 runs
Codon Mandelbrot Set
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
For test run or plot (uncomment code in the file)
CODON_PYTHON=/opt/homebrew/opt/python@3.11/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codon
Build and run
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json './benchmarks/multibrot_set/multibrot_codon'
RESULT:
Benchmark 1: ./benchmarks/multibrot_set/multibrot_codon
Time (mean ± σ): 44184.7 µs ± 1142.0 µs [User: 248773.9 µs, System: 72935.3 µs]
Range (min … max): 42963.8 µs … 46456.2 µs 10 runs
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json './benchmarks/multibrot_set/multibrot_codon_par'
Summary Mandelbrot Set
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.png
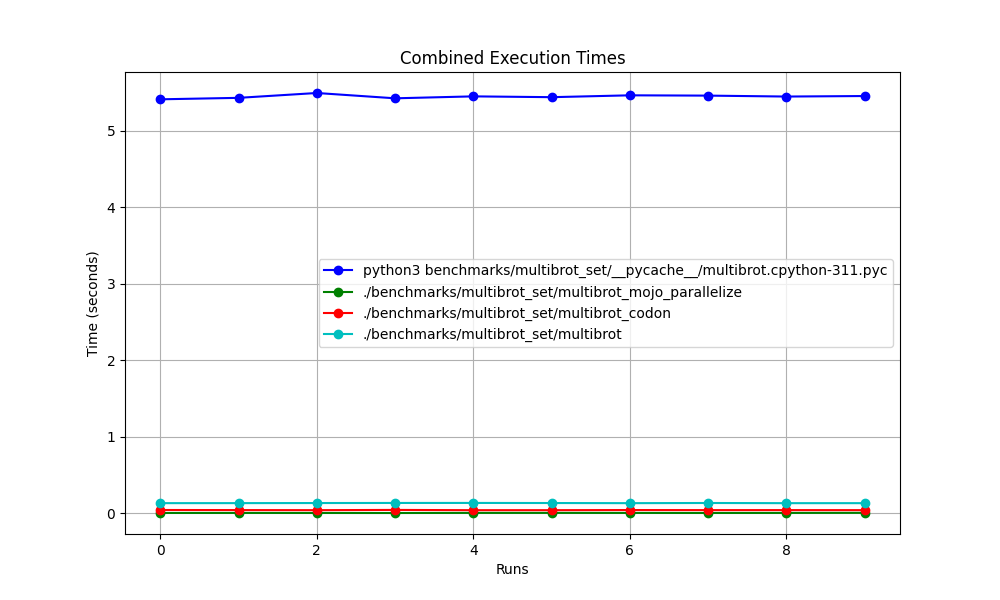
Advanced statistics
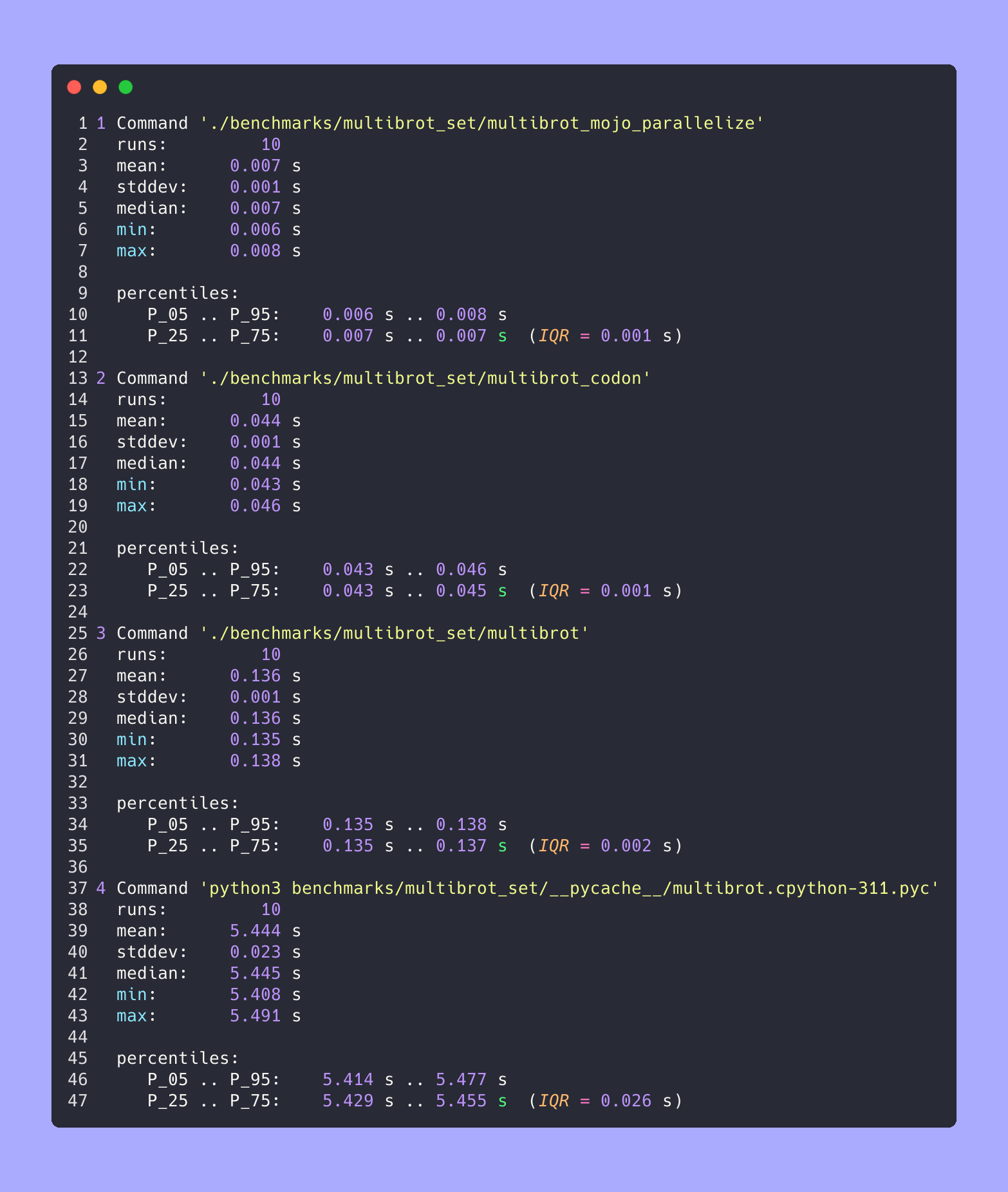
All together
Zoomed
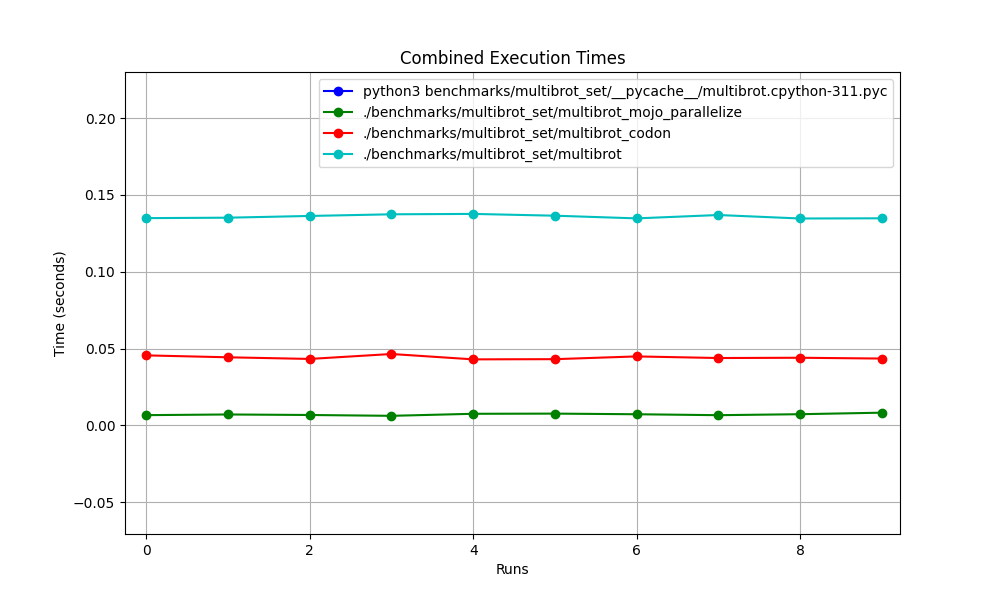
Detailed one by one
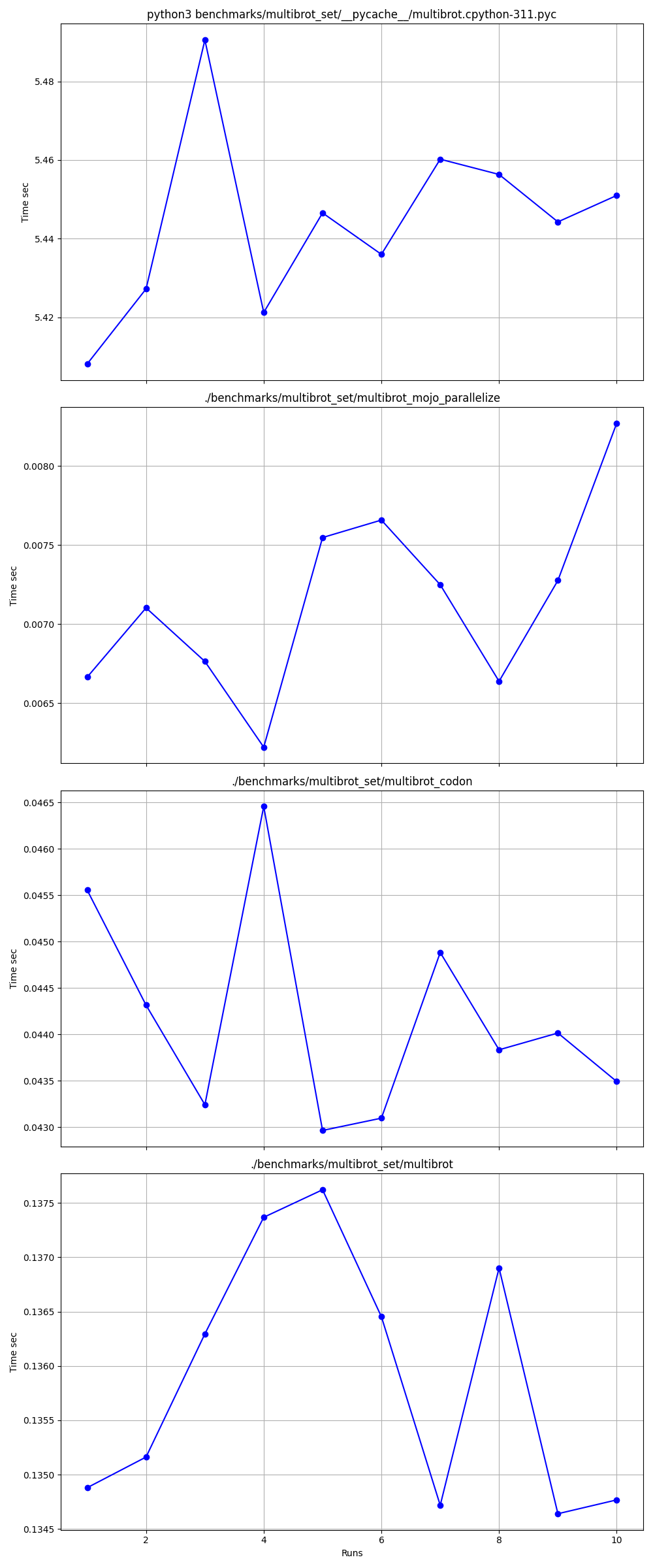
Places
- Mojo (parallelize)
- Codon
- Mojo
- Python
Links:
Mandelbrot = Multibrot with power = 2
z = z**power + c # You can change this for different set
Awesome Mojo🔥 code
Binary Search Algorithm
In computer science, binary search algorithm, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array.
Let’s do some code with Python, Mojo🔥, Swift, V, Julia, Nim, Zig.
Note: For Python and Mojo versions, I leave some optimization and make the code similar for measurement and comparison.
Python Binary Search
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple(i for i in range(SIZE)) # Make it aka at compile-time.
def python_binary_search(element: int, array: List[int]) -> int:
start = 0
stop = len(array) - 1
while start <= stop:
index = (start + stop) // 2
pivot = array[index]
if pivot == element:
return index
elif pivot > element:
stop = index - 1
elif pivot < element:
start = index + 1
return -1
def test_python_binary_search():
_ = python_binary_search(SIZE - 1, COLLECTION)
print(
"Average execution time of func in sec",
timeit.timeit(lambda: test_python_binary_search(), number=MAX_ITERS),
)
Mojo🔥 Binary Search
"""Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search(element: Int, array: DynamicVector[Int]) -> Int:
var start = 0
var stop = len(array) - 1
while start <= stop:
let index = (start + stop) // 2
let pivot = array[index]
if pivot == element:
return index
elif pivot > element:
stop = index - 1
elif pivot < element:
start = index + 1
return -1
@parameter # statement runs at compile-time.
fn get_collection() -> DynamicVector[Int]:
var v = DynamicVector[Int](SIZE)
for i in range(SIZE):
v.push_back(i)
return v
fn test_mojo_binary_search() -> F64:
fn test_closure():
_ = mojo_binary_search(SIZE - 1, get_collection())
return F64(Benchmark(NUM_WARMUP, MAX_ITERS).run[test_closure]()) / 1e9
print(
"Average execution time of func in sec ",
test_mojo_binary_search(),
)
It is the first binary search written in Mojo🔥by community (@ego) and posted in mojo-chat.
Swift Binary Search
func binarySearch(items: [Int], elem: Int) -> Int {
var low = 0
var high = items.count - 1
var mid = 0
while low <= high {
mid = Int((high + low) / 2)
if items[mid] < elem {
low = mid + 1
} else if items[mid] > elem {
high = mid - 1
} else {
return mid
}
}
return -1
}
let items = [1, 2, 3, 4, 0].sorted()
let res = binarySearch(items: items, elem: 4)
print(res)
Julia Binary Search
function binarysearch(lst::Vector{T}, val::T) where T
low = 1
high = length(lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end
Nim Binary Search
proc binarySearch[T](a: openArray[T], key: T): int =
var b = len(a)
while result < b:
var mid = (result + b) div 2
if a[mid] < key: result = mid + 1
else: b = mid
if result >= len(a) or a[result] != key: result = -1
let res = @[2,3,4,5,6,7,8,9,10,12,14,16,18,20,22,25,27,30]
echo binarySearch(res, 10)
Zig Binary Search
const std = @import("std");
fn binarySearch(comptime T: type, arr: []const T, target: T) ?usize {
var lo: usize = 0;
var hi: usize = arr.len - 1;
while (lo <= hi) {
var mid: usize = (lo + hi) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
lo = mid + 1;
} else {
hi = mid - 1;
}
}
return null;
}
V Binary Search
fn binary_search(a []int, value int) int {
mut low := 0
mut high := a.len - 1
for low <= high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return -1
}
fn main() {
search_list := [1, 2, 3, 5, 6, 7, 8, 9, 10]
println(binary_search(search_list, 9))
}
Bonus V Breadth First Search Path
fn breadth_first_search_path(graph map[string][]string, vertex string, target string) []string {
mut path := []string{}
mut visited := []string{init: vertex}
mut queue := [][][]string{}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][0][0]
path = queue[idx][1]
queue.delete(idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path.clone()
if child !in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main() {
graph := map{
'A': ['B', 'C']
'B': ['A', 'D', 'E']
'C': ['A', 'F']
'D': ['B']
'E': ['B', 'F']
'F': ['C', 'E']
}
println('Graph: $graph')
path := breadth_first_search_path(graph, 'A', 'F')
println('The shortest path from node A to node F is: $path')
assert path == ['A', 'C', 'F']
}
Fizz buzz
- Leetcode Fizz buzz problem
- Wikipedia Fizz buzz
- Add some optimisation, according to a Wikipedia problem statement.
Python Fizz buzz
import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz(): # Make it aka at compile-time.
res = []
for n in range(1, SIZE+1):
if (n % 3 == 0) and (n % 5 == 0):
s = "FizzBuzz"
elif n % 3 == 0:
s = "Fizz"
elif n % 5 == 0:
s = "Buzz"
else:
s = str(n)
res.append(s)
return res
DATA = _fizz_buzz()
def fizz_buzz():
print("\n".join(DATA))
print(
"Average execution time of Python func in sec",
timeit.timeit(lambda: fizz_buzz(), number=MAX_ITERS),
)
# Average execution time of Python func in sec 0.005334990004485007
Clojure Fizz buzz
(import '[java.io OutputStream])
(require '[clojure.java.io :as io])
(def devnull (io/writer (OutputStream/nullOutputStream)))
(defmacro timeit [n expr]
`(with-out-str (time
(dotimes [_# ~(Math/pow 1 n)]
(binding [*out* devnull]
~expr)))))
(defmacro macro-fizz-buzz [n]
`(fn []
(print
~(apply str
(for [i (range 1 (inc n))]
(cond
(zero? (mod i 15)) "FizzBuzz\n"
(zero? (mod i 5)) "Buzz\n"
(zero? (mod i 3)) "Fizz\n"
:else (str i "\n")))))))
(print (timeit 100 (macro-fizz-buzz 100)))
;; "Elapsed time: 0.175486 msecs"
;; Average execution time of Clojure func in sec 0.000175486 seconds
Mojo🔥Fizz buzz
from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@parameter # statement runs at compile-time.
fn _fizz_buzz() -> String:
var res: String = ""
for n in range(1, SIZE+1):
if (n % 3 == 0) and (n % 5 == 0):
res += "FizzBuzz"
elif n % 3 == 0:
res += "Fizz"
elif n % 5 == 0:
res += "Buzz"
else:
res += String(n)
res += "\n"
return res
fn fizz_buzz():
print(_fizz_buzz())
fn run_benchmark() -> F64:
fn _closure():
_ = fizz_buzz()
return F64(Benchmark(NUM_WARMUP, MAX_ITERS).run[_closure]()) / 1e9
print(
"Average execution time of func in sec ",
run_benchmark(),
)
# Average execution time of func in sec 0.000104 🔥
It is the first Fizz buzz written in Mojo🔥 ever by community (@Ego).
Merge sort
We will use algorithm from vell-known reference for algorithms book Introduction to Algorithms A3
Its fame has led to the common use of the abbreviation “CLRS” (Cormen, Leiserson, Rivest, Stein), or, in the first edition, “CLR” (Cormen, Leiserson, Rivest).
Chapter 2 “2.3.1 The divide-and-conquer approach”.
Python Merge sort
%%python
import timeit
MAX_ITERS = 100
def merge(A, p, q, r):
n1 = q - p + 1
n2 = r - q
L = [None] * n1
R = [None] * n2
for i in range(n1):
L[i] = A[p + i]
for j in range(n2):
R[j] = A[q + 1 + j]
i = 0
j = 0
k = p
while i < n1 and j < n2:
if L[i] <= R[j]:
A[k] = L[i]
i += 1
else:
A[k] = R[j]
j += 1
k += 1
while i < n1:
A[k] = L[i]
i += 1
k += 1
while j < n2:
A[k] = R[j]
j += 1
k += 1
def merge_sort(A, p, r):
if p < r:
q = (p + r) // 2
merge_sort(A, p, q)
merge_sort(A, q + 1, r)
merge(A, p, q, r)
def run_benchmark_merge_sort():
A = [14, 72, 50, 83, 18, 20, 13, 30, 17, 87, 94, 65, 24, 99, 70, 44, 5, 12, 74, 6, 32, 63, 91, 88, 43, 54, 27, 39, 64, 78, 29, 62, 58, 59, 61, 89, 2, 15, 41, 9, 93, 90, 23, 96, 73, 14, 8, 28, 11, 42, 77, 34, 52, 80, 57, 84, 21, 60, 66, 40, 7, 85, 47, 98, 97, 35, 82, 36, 49, 3, 68, 22, 67, 81, 56, 71, 4, 38, 69, 95, 16, 48, 1, 31, 75, 19, 10, 25, 79, 45, 76, 33, 53, 55, 46, 37, 26, 51, 92, 86]
merge_sort(A, 0, len(A)-1)
print(
"Average execution time of Python `merge_sort` in sec",
timeit.timeit(lambda: run_benchmark_merge_sort(), number=MAX_ITERS),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort():
A = [14, 72, 50, 83, 18, 20, 13, 30, 17, 87, 94, 65, 24, 99, 70, 44, 5, 12, 74, 6, 32, 63, 91, 88, 43, 54, 27, 39, 64, 78, 29, 62, 58, 59, 61, 89, 2, 15, 41, 9, 93, 90, 23, 96, 73, 14, 8, 28, 11, 42, 77, 34, 52, 80, 57, 84, 21, 60, 66, 40, 7, 85, 47, 98, 97, 35, 82, 36, 49, 3, 68, 22, 67, 81, 56, 71, 4, 38, 69, 95, 16, 48, 1, 31, 75, 19, 10, 25, 79, 45, 76, 33, 53, 55, 46, 37, 26, 51, 92, 86]
A.sort()
print(
"Average execution time of Python builtin `sort` in sec",
timeit.timeit(lambda: run_benchmark_sort(), number=MAX_ITERS),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494
Mojo🔥 Merge sort
from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge(inout A: DynamicVector[Int], p: Int, q: Int, r: Int):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector[Int](n1)
var R = DynamicVector[Int](n2)
for i in range(n1):
L[i] = A[p + i]
for j in range(n2):
R[j] = A[q + 1 + j]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2:
if L[i] <= R[j]:
A[k] = L[i]
i += 1
else:
A[k] = R[j]
j += 1
k += 1
while i < n1:
A[k] = L[i]
i += 1
k += 1
while j < n2:
A[k] = R[j]
j += 1
k += 1
fn merge_sort(inout A: DynamicVector[Int], p: Int, r: Int):
if p < r:
let q = (p + r) // 2
merge_sort(A, p, q)
merge_sort(A, q + 1, r)
merge(A, p, q, r)
@parameter
fn create_vertor() -> DynamicVector[Int]:
let st = StaticTuple[MAX_ITERS, Int](14, 72, 50, 83, 18, 20, 13, 30, 17, 87, 94, 65, 24, 99, 70, 44, 5, 12, 74, 6, 32, 63, 91, 88, 43, 54, 27, 39, 64, 78, 29, 62, 58, 59, 61, 89, 2, 15, 41, 9, 93, 90, 23, 96, 73, 14, 8, 28, 11, 42, 77, 34, 52, 80, 57, 84, 21, 60, 66, 40, 7, 85, 47, 98, 97, 35, 82, 36, 49, 3, 68, 22, 67, 81, 56, 71, 4, 38, 69, 95, 16, 48, 1, 31, 75, 19, 10, 25, 79, 45, 76, 33, 53, 55, 46, 37, 26, 51, 92, 86)
var v = DynamicVector[Int](st.__len__())
for i in range(st.__len__()):
v.push_back(st[i])
return v
fn run_benchmark_merge_sort() -> F64:
fn _closure():
var A = create_vertor()
merge_sort(A, 0, len(A)-1)
return F64(Benchmark(NUM_WARMUP, MAX_ITERS).run[_closure]()) / 1e9
print(
"Average execution time of Mojo🔥 `merge_sort` in sec ",
run_benchmark_merge_sort(),
)
# Average execution time of Mojo🔥 `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort() -> F64:
fn _closure():
var A = create_vertor()
sort(A)
return F64(Benchmark(NUM_WARMUP, MAX_ITERS).run[_closure]()) / 1e9
print(
"Average execution time of Mojo🔥 builtin `sort` in sec ",
run_benchmark_sort(),
)
# Average execution time of Mojo🔥 builtin `sort` in sec 2.988e-06
You can use it like:
# Usage: merge_sort
var A = create_vertor()
merge_sort(A, 0, len(A)-1)
print(len(A))
print(A[0], A[99])
Builtin from Sort import sort quicksort a little bit faster than our implementation,
but we can optimize it during deep in language and as usual with algorithms =) and programming paradigms.
- Multithreaded Algorithms, Multithreaded merge sort at pages 797, 803 of the book CLRS above
- Three Hungarians’ Algorithm
- Use insertion sort for small subarrays, hybrid merge sort
- Merge in a different direction
- Use an adaptive approach
- Implement in-place merging
- Optimize memory access
- Mojo Stdlib Functional
- Tiled merge sort like in Tiling Matmul
- Parallel multiway merge sort
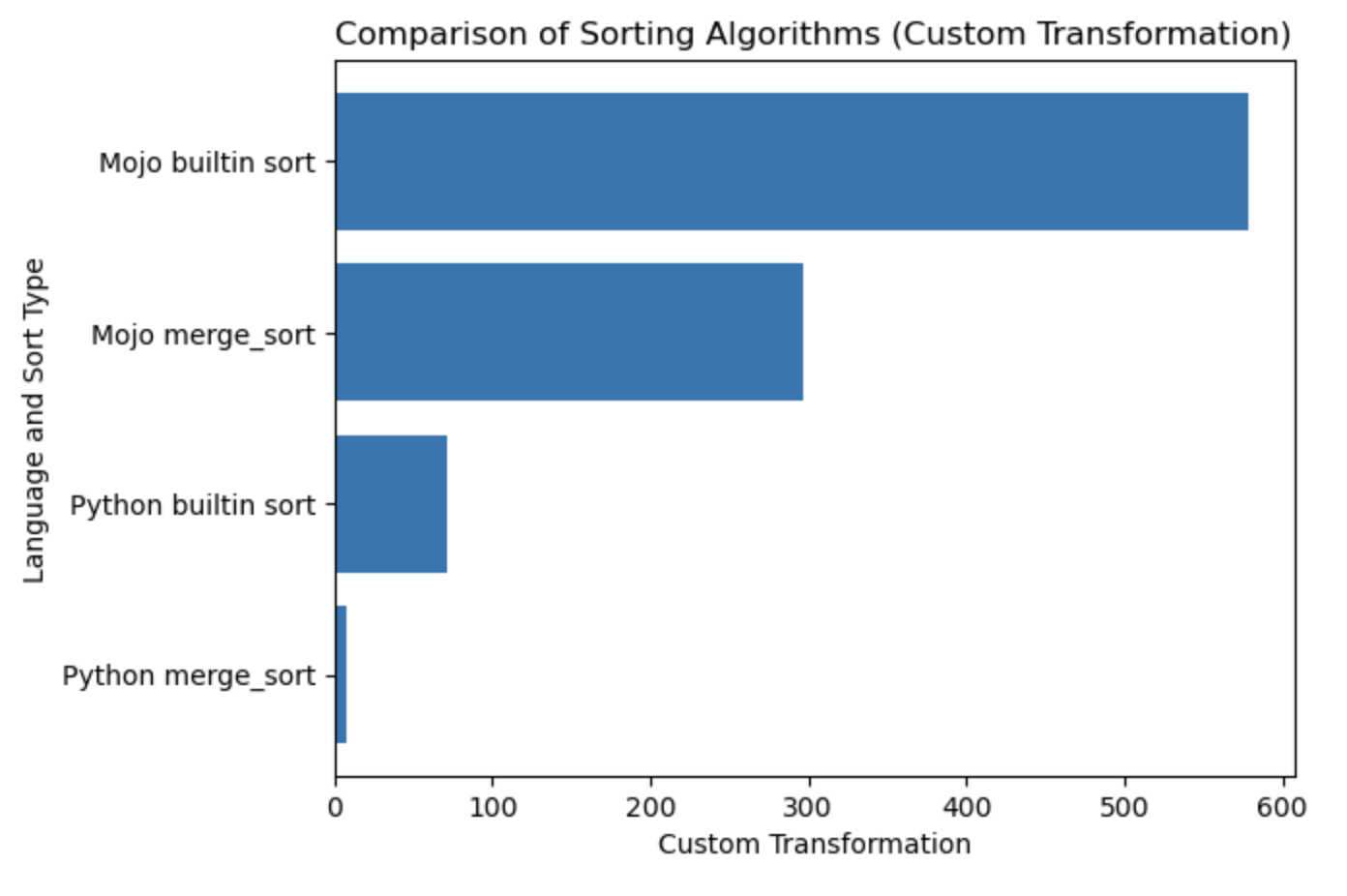
Summary for sorting algorithms merge sort and quicksort
| Lang | sec |
|---|---|
| Python merge_sort | 0.019136679 |
| Python builtin sort | 0.000199228 |
| Mojo merge_sort | 0.000011346 |
| Mojo builtin sort | 0.000002988 |
Let’s build a plot for this table.
#%%python
import matplotlib.pyplot as plt
import numpy as np
languages = ['Python merge_sort', 'Python builtin sort', 'Mojo merge_sort', 'Mojo builtin sort']
seconds = [0.019136679, 0.000199228, 0.000011346, 0.000002988]
# Apply a custom transformation to the values
transformed_seconds = [np.sqrt(1 / x) for x in seconds]
plt.barh(languages, transformed_seconds)
plt.xlabel('Custom Transformation')
plt.ylabel('Language and Sort Type')
plt.title('Comparison of Sorting Algorithms (Custom Transformation)')
plt.show()
Plot notes, more is better and faster.
Programming manual
Parameterization[]: compile time meta-programming
I strongly recommended start from here HelloMojo and understand [parameter] and [parameter expressions] parameterization here. Like in this example:
fn concat[len1: Int, len2: Int](lhs: MySIMD[len1], rhs: MySIMD[len2]) -> MySIMD[len1+len2]:
let result = MySIMD[len1 + len2]()
for i in range(len1):
result[i] = lhs[i]
for j in range(len2):
result[len1 + j] = rhs[j]
return result
let a = MySIMD[2](1, 2)
let x = concat[2,2](a, a)
x.dump()
Compile time [Parameters]: fn concat[len1: Int, len2: Int].
Run time (Args): fn concat(lhs: MySIMD, rhs: MySIMD).
Parameters PEP695 syntax in square [] brackets.
Now in Python:
def func(a: _T, b: _T) -> _T:
...
Now in Mojo🔥:
def func[T](a: T, b: T) -> T:
...
[Parameters] are named and have types like normal values in a Mojo program, but parameters[] are evaluated at compile time.
The runtime program may use the value of [parameters] - because the parameters are resolved at compile time before they are needed by the runtime program - but the compile time parameter expressions may not use runtime values.
Self type from PEP673
fn __sub__(self, rhs: Self) -> Self:
let result = MySIMD[size]()
for i in range(size):
result[i] = self[i] - rhs[i]
return result
In the docs you can find word Fields it is aka class Attributes in the Python.
So, you call them with dot.
from DType import DType
let bool_type = DType.bool
Data Type Model and alias
- The base construct block is DType. Some analogies:
from DType import DType
DType.si8
- Then you can wrap it with SIMD struct aka container.
- SIMD Single Instruction, Multiple Data and SIMD at wikipedia
from DType import DType
from SIMD import SIMD, SI8
alias MY_SIMD_DType_si8 = SIMD[DType.si8, 1]
alias MY_SI8 = SI8
print(MY_SIMD_DType_si8 == MY_SI8)
# true
- Then a sequence of these types you can wrap with a container DynamicVector or similar.
from DType import DType
from SIMD import SIMD, SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector[SIMD[DType.si8, 1]]
alias b = DynamicVector[SI8]
print(a == b)
print(a == String)
print(b == String)
# all true
So the String is only alias for a something like DynamicVector[SIMD[DType.si8, 1]].
VariadicList for destructuring/unpacking/accessing arguments
from List import VariadicList
fn destructuring_arguments(*args: Int):
let my_var_list = VariadicList(args)
for i in range(len(my_var_list)):
print("argument", i, ":", my_var_list[i])
destructuring_arguments(1, 2, 3, 4)
It is very useful for creating initial collections. We can write like this:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor() -> DynamicVector[Int]:
let st = StaticTuple[4, Int](1, 2, 3, 4)
var v = DynamicVector[Int](st.__len__())
for i in range(st.__len__()):
v.push_back(st[i])
return v
v = create_vertor()
print(v[0], v[3])
# or
from List import VariadicList
fn create_vertor() -> DynamicVector[Int]:
let var_list = VariadicList(1, 2, 3, 4)
var v = DynamicVector[Int](len(var_list))
for i in range(len(var_list)):
v.push_back(var_list[i])
return v
v = create_vertor()
print(v[0], v[3])
Read more about function def and fn
String
from String import String
# String concatenation
print(String("'") + String(1) + "'\n")
# Python's join
print(String("|").join("a", "b", "c"))
# String format
from IO import _printf as print
let x: Int = 1
print("'%i'\n", x.value)
String and builtin slice
For a string you can use Builtin Slice with format string slice[start:end:step].
from String import String
let hello_mojo = String("Hello Mojo!")
print("Till the end:", hello_mojo[0::])
print("Before last 2 chars:", hello_mojo[0:-2])
print("From start to the end with step 2:", hello_mojo[0::2])
print("From start to the before last with step 3:", hello_mojo[0:-1:3])
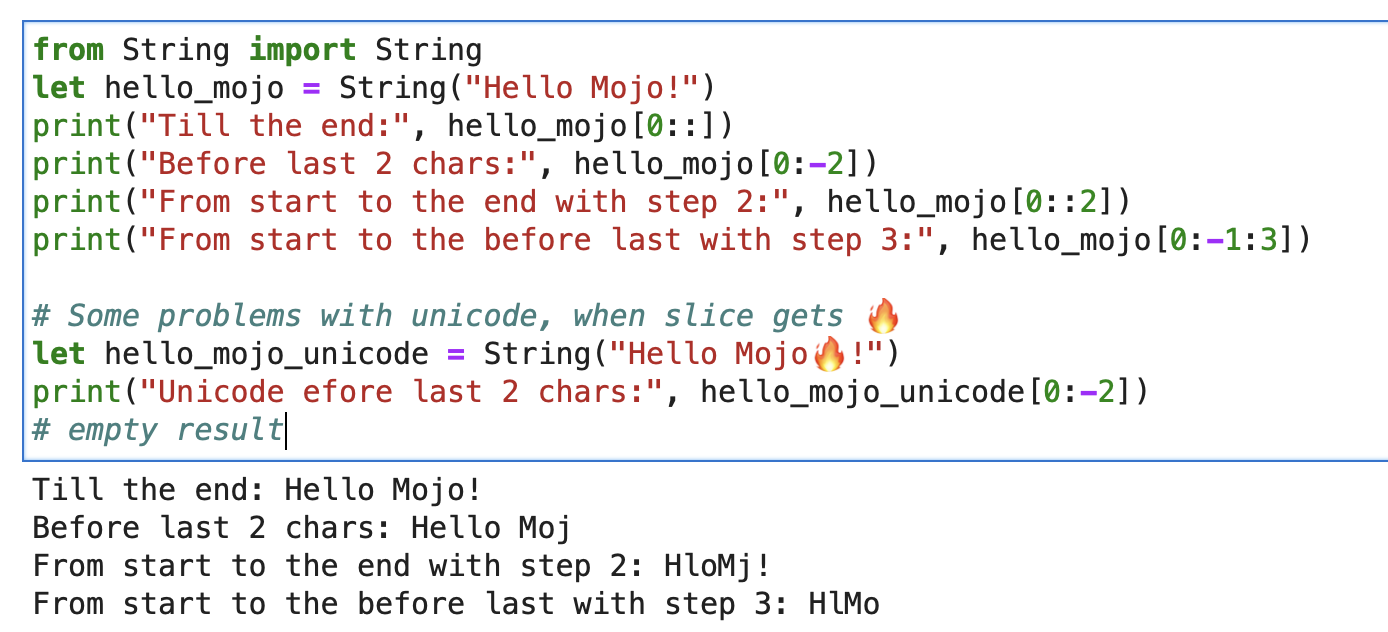
There is some problem with unicode, when slicing 🔥:
let hello_mojo_unicode = String("Hello Mojo🔥!")
print("Unicode efore last 2 chars:", hello_mojo_unicode[0:-2])
# no result, silents
Here is an explanation and some discussion.
mbstowcs - convert a multibyte string to a wide-character string
Mojo🔥decorators
@value
struct decorator aka Python @dataclass.
It will generate methods __init__, __copyinit__, __moveinit__ for you automatically.
@value
struct dataclass:
var name: String
var age: Int
Note that the @value decorator only works on types whose members are copyable and/or movable.
@value(“trivial”)
@register_passable(“trivial”)
Trivial types. This decorator tells Mojo that the type should be copyable __copyinit__ and movable __moveinit__.
It also tells Mojo to prefer to pass the value in CPU registers.
Allows structs to opt-in to being passed in a register instead of passing through memory.
@register_passable("trivial")
struct Int:
var value: __mlir_type.`!pop.scalar<index>`
@always_inline
Decorators that provide full control over compiler optimizations. Instructs compiler to always inline this function when it’s called.
@always_inline
fn foo(x: Int, y: Int) -> Int:
return x + y
fn bar(z: Int):
let r = foo(z, z) # This call will be inlined
@parameter
It can be placed on nested functions that capture runtime values to create “parametric” capturing closures. It allows closures that capture runtime values to be passed as parameter values.
Decorators combination
@always_inline
@parameter
fn test(): return
Casting
Some casting examples
s: StringLiteral
let p = DTypePointer[DType.si8](s.data()).bitcast[DType.ui8]()
var result = 0
result += ((p.simd_load[64](offset) >> 6) != 0b10).cast[DType.ui8]().reduce_add().to_int()
let rest_p: DTypePointer[DType.ui8] = stack_allocation[simd_width, UI8, 1]()
from Bit import ctlz
s: String
i: Int
let code = s.buffer.data.load(i)
let byte_length_code = ctlz(~code).to_int()
Stack, Mem, Pointer, Allocation, Free
DTypePointer, Heap and Stack
DTypePointer - store an address with a given DType, allowing you to allocate, load and modify data with convenient access to SIMD operations.
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer[DType.ui8].alloc(8)
memset_zero(my_pointer_on_heap, 8)
# `stack or register`
var data = my_pointer_on_heap.simd_load[8](0)
print(data)
rand(my_pointer_on_heap, 4)
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap.simd_load[8](0)
print(data)
# simd_load and simd_store
var half = my_pointer_on_heap.simd_load[4](0)
half = half + 1
my_pointer_on_heap.simd_store[4](4, half)
print(my_pointer_on_heap.simd_load[8](0))
# Pointer move back
my_pointer_on_heap -= 1
print(my_pointer_on_heap.simd_load[8](0))
# Mast free memory
my_pointer_on_heap.free()
Struct can minimaze potential dangerous of pointers by limiting scoup.
Excellent article on Mojo Dojo blog about DTypePointer here
Plus his example Matrix Struct and DTypePointer
Pointer
Pointer store an address to any register_passable type, and allocate n amount of them to the heap.
from Pointer import Pointer
from Memory import memset_zero
from String import String
@register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord: # memory-only type
var x: UI8
var y: UI8
var p1 = Pointer[Coord].alloc(2)
memset_zero(p1, 2)
var coord = p1[0] # is an identifier to memory on the stack or in a register
print(coord.x)
# Store the value
coord.x = 5
coord.y = 5
print(coord.x)
# We need to store the data.
p1.store(0, coord)
print(p1[0].x)
# Mast free memory
p1.free()
Full article about Pointer
Plus exemple Pointer and Struct
Advanced Mojo🔥features and Intrinsics module
Modular Intrinsics it is some kind of execution backends:
- Mojo🔥compiler features
- LLVM intrinsic maybe this one
- External call like libc
- MLIR Multi-Level Intermediate Representation
Mojo🔥-> MLIR Dialects -> execution backends with optimization code and architectures.
MLIR is a compiler infrastructure witch implementing various transformation and optimization passes for different programming languages and architectures.
Syscalls
MLIR itself does not directly provide functionality for interacting with operating system syscalls.
Which are low-level interfaces to operating system services, are typically handled at the level of the target programming language or the operating system itself. MLIR is designed to be language-and-target-agnostic, and its primary focus is on providing an intermediate representation for performing optimizations. To perform operating system syscalls in MLIR, we need to use a target-specific backend.
But with these execution backends, basically, we have access to OS syscalls.
And we have the whole world of C/LLVM/Python stuff under the hood.
Lets have same quick look on it in practice:
from OS import getenv
print(getenv("PATH"))
print(getenv(StringRef("PATH")))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call["getenv", StringRef](StringRef("PATH"))
print(path1.data)
var path2 = external_call["getenv", StringRef]("PATH")
print(path2.data)
let abs_10 = external_call["abs", SI8, Int](-10)
print(abs_10)
In this simple example we used external_call to get OS environment variable with a casting type between Mojo and libc functions.
Pretty cool, yeah!
I have a lot of ideas from this topic and I am eagerly awaiting the opportunity to implement them soon. Taking action can lead to amazing outcomes =)
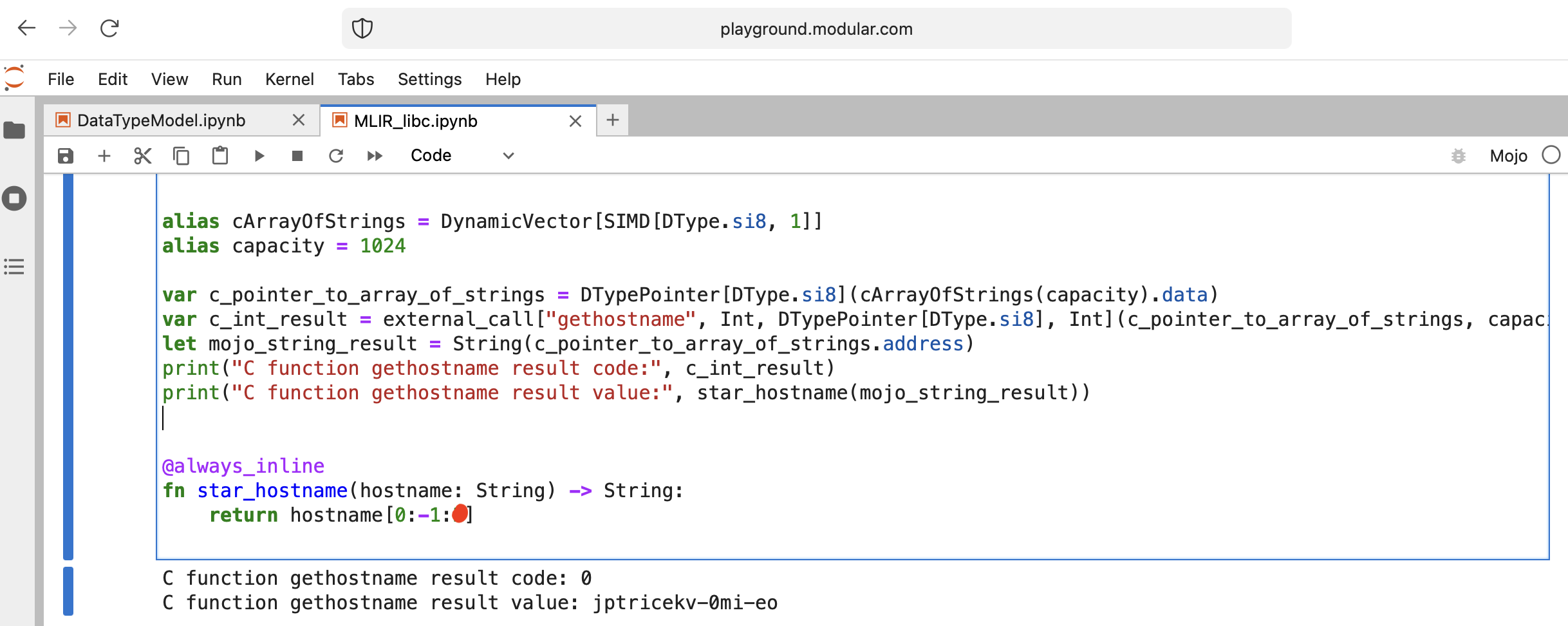
MLIR libc gethostname
Let’s do something interesting - call libc function gethostname.
Function has this interface int gethostname (char *name, size_t size).
For that we can use helper function external_call from Intrinsics module or write own MLIR.
Let’s go code:
from Intrinsics import external_call
from SIMD import SIMD, SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer, Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector[SIMD[DType.si8, 1]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer[DType.si8](cArrayOfStrings(capacity).data)
var c_int_result = external_call["gethostname", Int, DTypePointer[DType.si8], Int](c_pointer_to_array_of_strings, capacity)
let mojo_string_result = String(c_pointer_to_array_of_strings.address)
print("C function gethostname result code:", c_int_result)
print("C function gethostname result value:", star_hostname(mojo_string_result))
@always_inline
fn star_hostname(hostname: String) -> String:
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname[0:-1:2]
Mojo🔥TCP Socket Server with PythonInterface
Let’s do some things for a WEB with Mojo🔥. We do not have Internet access at playground.modular.com But we can steal do some interesting stuff like TCP on one machine.
Let’s write the first TCP client-server code in Mojo🔥 with PythonInterface
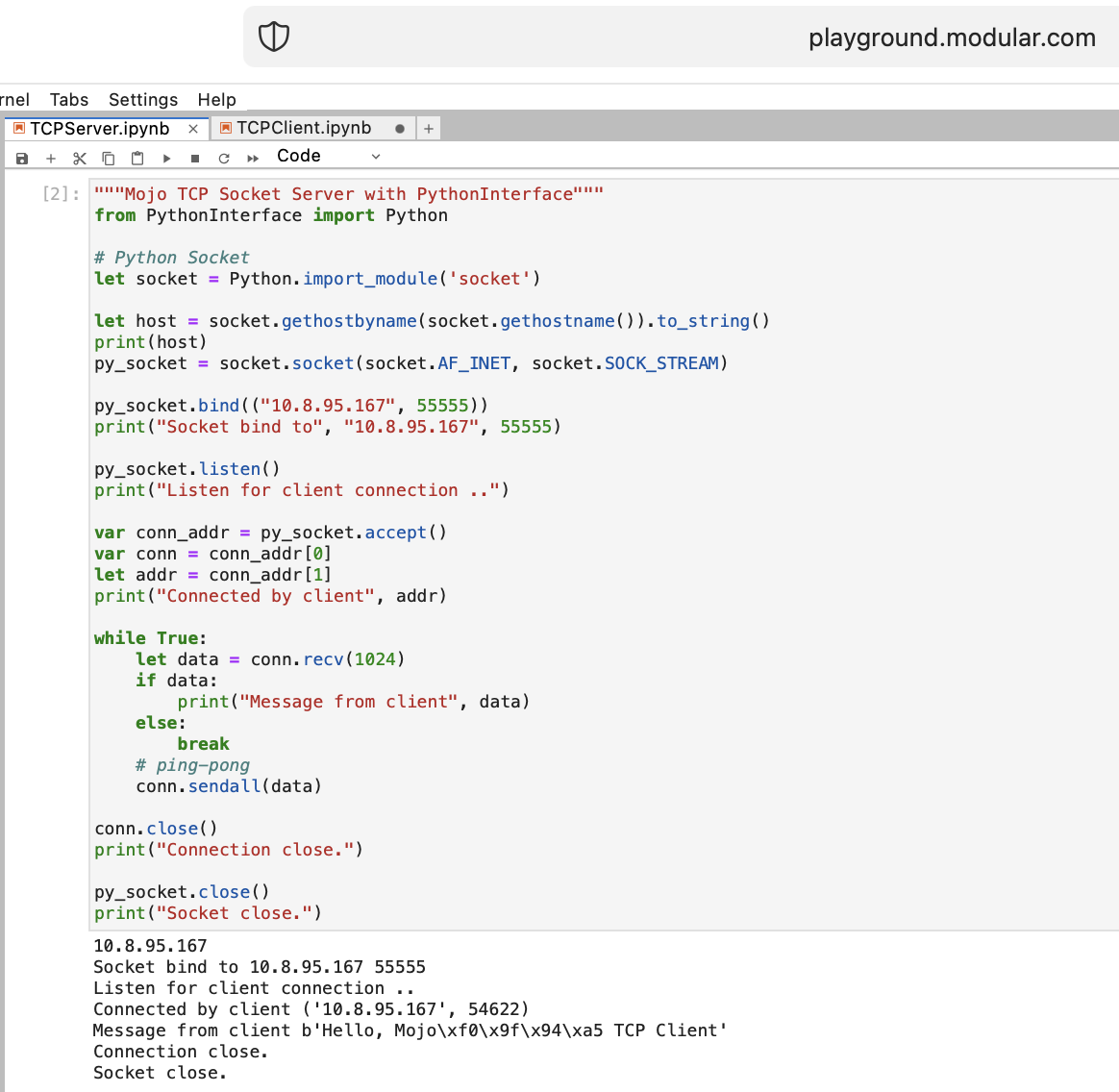
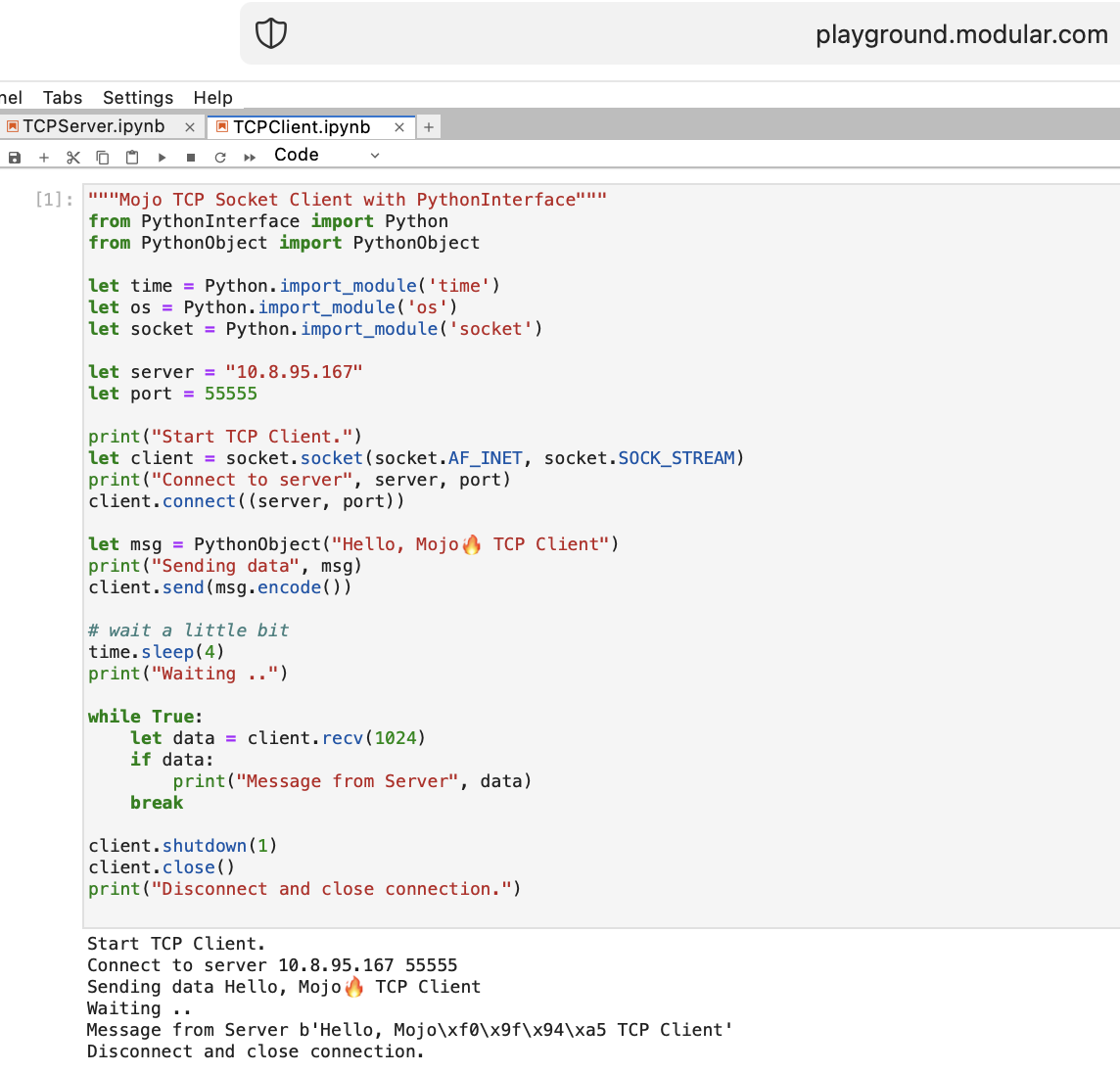
You should create two separate notebooks, and run TCPSocketServer first then TCPSocketClient.
Python version of this code almost the same, except:
withsyntaxletassigning-
and destructuring like
a, b = (1, 2) - Pytohn socket low-level networking interface
- Pytohn socketserver framework for network servers
Mojo🔥FastAPI with PythonInterface
After TCP Server in Mojo🔥 we are going forward =)
It’s crazy, but let’s try to run modern Python web server FastAPI with Mojo🔥!
Preparation
We need to upload FastAPI code to playground. So, on your local machine do
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz web
and upload web.tar.gz to playground via web interface.
Then we need to install it, just put into proper folder:
%%python
import os
import site
site_packages_path = site.getsitepackages()[0]
# install fastapi
os.system(f"tar xzf web.tar.gz -C {site_packages_path}")
os.system(f"cp -r {site_packages_path}/web/* {site_packages_path}/")
os.system(f"ls {site_packages_path} | grep fastapi")
# clean packages
os.system(f"rm -rf {site_packages_path}/web")
os.system(f"rm web.tar.gz")
Mojo🔥FastAPI Server
from PythonInterface import Python
# Python fastapi
let fastapi = Python.import_module("fastapi")
let uvicorn = Python.import_module("uvicorn")
var app = fastapi.FastAPI()
var router = fastapi.APIRouter()
# tricky part
let py = Python()
let py_code = """lambda: 'Hello Mojo🔥!'"""
let py_obj = py.evaluate(py_code)
print(py_obj)
router.add_api_route("/mojo", py_obj)
app.include_router(router)
print("Start FastAPI WEB Server")
uvicorn.run(app)
print("Done")
Mojo🔥FastAPI Client
from PythonInterface import Python
let http_client = Python.import_module("http.client")
let conn = http_client.HTTPConnection("localhost", 8000)
conn.request("GET", "/mojo")
let response = conn.getresponse()
print(response.status, response.reason, response.read())
As usual, you should create two separate notebooks, and run FastAPI first then FastAPIClient.
- Mojo🔥FastAPI Server
- Mojo🔥FastAPI Server Jupyter Notebook
- Mojo🔥FastAPI Client
- Mojo🔥FastAPI Client Jupyter Notebook
There are a lot of open questions, but basically we achieve the goal.
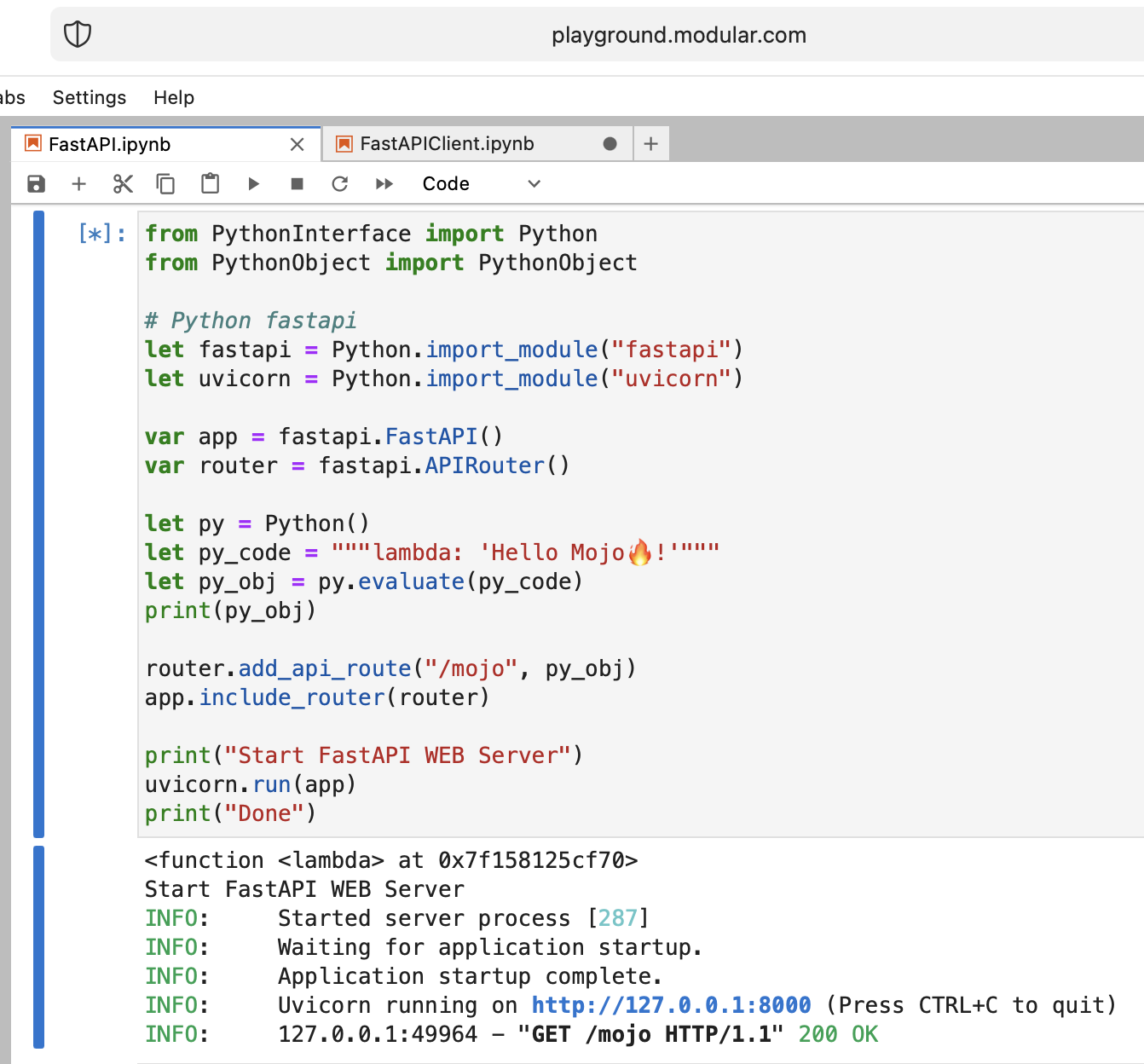
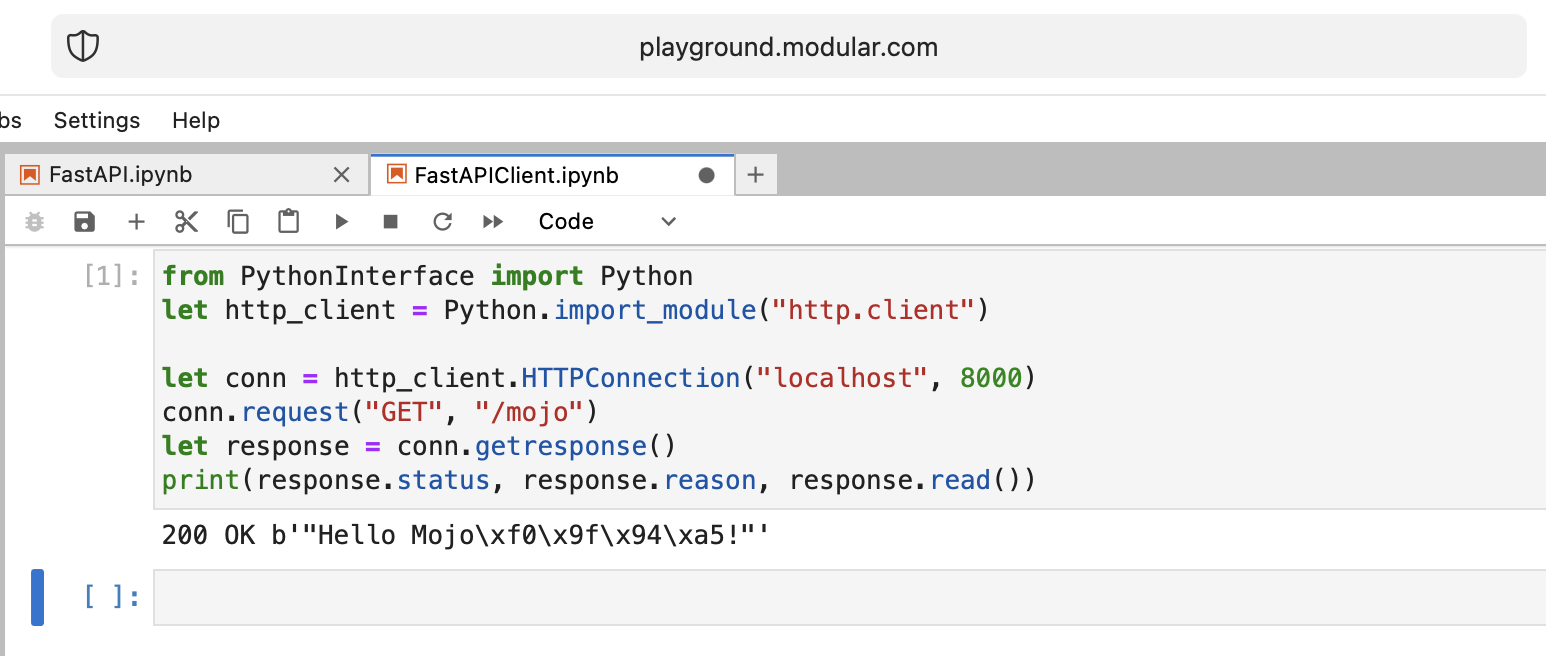
Mojo🔥 well done!
Some open questions:
- Lack of Python syntax sugar
- Lack of Mojo types implicitly converted into Python objects
- How to pass Mojo function into Python space/function
from PythonInterface import Python
let pyfn = Python.evaluate("lambda x, y: x+y")
let functools = Python.import_module("functools")
print(functools.reduce(pyfn, [1, 2, 3, 4]))
# How to, without Mojo pyfn.so?
def pyfn(x, y):
retyrn x+y
The future looks very optimistic!
Links:
Code implementation
Radiative transfer
Benchmark Mojo vs Numba by Nick Wogan
Instant and DateTimeLocal
Time utils by Samay Kapadia @Zalando
IDEA
Connecting to your mojo playground from VSCode or DataSpell
Python Interface and reading files
by Maxim Zaks
from String import String
from PythonInterface import Python
let pathlib = Python.import_module('pathlib')
let txt = pathlib.Path('nfl.csv').read_text()
let s: String = txt.to_string()
Pointer data
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String, chr
let hello = "hello"
let pointer = Pointer(hello.data())
print("variant 1")
var result = String()
for i in range(len(hello)):
result += chr(pointer.bitcast[Int8]().offset(i).load().to_int())
print(result)
print("variant 2")
print(StringRef(hello.data()))
print("variant 3")
print(StringRef(pointer.address))
print("variant 4")
let pm: Pointer[__mlir_type.`!pop.scalar<si8>`] = Pointer(hello.data())
print(StringRef(pm.address))
print("variant 5")
print(String(pointer.address))
print("variant 6")
let x = Buffer[8, DType.int8](pointer)
let array = x.simd_load[10](0)
var result = String()
for i in range(len(array)):
result += chr(array[i].to_int())
print(result)
Code share from Mojo Playground
- From the Mojo Playground,
right clickthe file in the explorer and pressOpen With > Editor - Right click in the editor,
select allandcopy - Create a new GitHub gist or put Jupyter notebook file into yor GitHub repository
- Paste in the contents and name the file with the Jupyter extension like test
.ipynb - Paste the link to the gist in the Discord chat
Github renders it properly, and then if someone wants to try out the code in their playground they can copy paste the raw code.
The Zen of Mojo🔥
Space for improvements
It is my personal view, so don’t judge me too harshly.
I can’t say that Mojo🔥 is an easy programming language for learning, like a Python as an example.
It requires a lot of understanding, patience and experience in any other programming languages.
If you want to build something not trivial, it will be hard but funny!
It has been 2 weeks since I embarked on this journey, and I am thrilled to share that I have now become well-acquainted with the Mojo🔥.
The intricacies of its structure and syntax have started to unravel before my eyes, and I am filled with a newfound understanding.
I am proud to say that I can now confidently craft code in this language, allowing me to bring to life a diverse range of ideas.
Major things to improve:
- Weak and unclear documentation.
- Lack of code examples. A good example is clojuredocs website.
- More explanation to the language paradigms
- Lack comparison to Python base things datatypes/functions/classes/expressions.
- Even though Mojo is superset of Python, the threshold of language entry is not so simple.
- A little bit raw, need some time for stabilizing language. Production release 1.0.
- Bugs, like in any one.
- Small standard library.
- Project Jupyter and notebooks environment. I understand that Jupyter plugin and custom kernel are a good solution, but it is makes development so slow.
- Not open-sourced yet. The community is waiting for open source compiler and REPL to start developing and producing libraries and applications. I think the community will easily rewrite the (bootstrapping) compiler from C++ to itself Mojo🔥.
Good and nice for win
- Modular team easily responds to requests/questions/letters/ideas
- Friendly and very smart community
- Problem-solving programming language with an idea to not create new syntax but deal with real word challenges.
- I don’t know about you, but I was waiting and researching a long time for a Mojo🔥. I have been tried a hundred of programming languages. The World is ready for the revolution and the future of computation and AI. I’m really into Mojo🔥, it excites, fascinates me, and I hope it does the same for you.
- I believe that a well-known distinguished leader Ph.D. Computer Science Chris Lattner can build things, systems, teams and change the future.
Modular and Mojo🔥 history and etymology
Mojo🔥 is a Modular Inc programming language. Why Mojo we discussed here.
About Company we know less, but it has a very cool name Modular,
which can be referred to:
All about computing, programming, AI/ML. A very good domain name that accurately describes the meaning of the Company.
There are some additional materials about Modular’s Brand Story and Helping Modular Humanize AI Through Brand
Additional materials
- Chris Lattner
- LLVM
- MLIR
- Circuit IR Compilers and Tools
- Cross Compile Compiler-rt
- The future of AI depends on Modularity
- The Architecture of Open Source Applications LLVM
- The Golden Age of Compiler Design in an Era of HW/SW Co-design by Dr. Chris Lattner
- LLVM in 100 Seconds
- Mojo Dojo
- Mojo Cheatsheet
- Counting chars with SIMD in Mojo
- History of programming languages
MLIR and low-level implementation
Python / C++
- Numpy
- Numba based on (LLVM)
- PyPy
- Google JAX based on (XLA)
- Ray
- Taichi Lang
- Codon
- CuPy
- Cython
- Pythran
- Mypyc
- Nuitka
- DeepSpeed
- Benchmarks for CPU and GPU performance high-performance Python libs
- Metaflow
- Accelerating experimentation with mlops
- nebuly-ai
- Numba compiler for Python bytecode, Numba IR into LLVM IR, Compile LLVM IR to machine code
AI
- Accelerated Computing
- ONNX open standard for machine learning
- ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator
- CUDA
- OpenCL
- SYCL
- Google Brain TensorFlow
- PyTorch
- TensorRT
- OpenaAI Triton language and compiler
- Made With ML
- Vertex AI
- Google TPU
- Sagemaker
- MLIR: accelerating AI with open-source infrastructure
- Apache TVM
Python hints
Todat I would like to tell story about Python Enum problem.
As a software engineers we often meet it in a WEB.
Assume we have this DataBase Schema (PostgreSQL) with status enum:
CREATE TYPE public.status_type AS ENUM (
'FIRST',
'SECOND'
);
In a Python code we need names and values as strings (assume we use GraphQL with some ENUM type for our frontend side), and we need to maintain their order and have ability to compare these enums:
order2.status > order1.status > 'FIRST'
So it’s a problem for most of common languages =) but we can use a little-known Python feature and override enum class method: __new__.
- But Why?
- Hm..
To assosiate each enum value with its INDEX!
MALE -> 1,FEMALE -> 2, like PostgreSQL do. - and How?
- Just COUNT its members with the
lenfunction!
import enum
from functools import total_ordering
@total_ordering
@enum.unique
class BaseUniqueSortedEnum(enum.Enum):
"""Base unique enum class with ordering."""
def __new__(cls, *args, **kwargs):
obj = object.__new__(cls)
obj.index = len(cls.__members__) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__(self) -> int:
return hash(
f"{self.__module__}_{self.__class__.__name__}_{self.name}_{self.value}"
)
def __eq__(self, other) -> bool:
self._check_type(other)
return super().__eq__(other)
def __lt__(self, other) -> bool:
self._check_type(other)
return self.index < other.index
def _check_type(self, other) -> None:
if type(self) != type(other):
raise TypeError(f"Different types of Enum: {self} != {other}")
class Dog(BaseUniqueSortedEnum):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat(BaseUniqueSortedEnum)
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog.BLOODHOUND < Dog.WEIMARANER
assert Dog.BLOODHOUND <= Dog.WEIMARANER
assert Dog.BLOODHOUND != Dog.WEIMARANER
assert Dog.BLOODHOUND == Dog.BLOODHOUND
assert Dog.WEIMARANER == Dog.WEIMARANER
assert Dog.WEIMARANER > Dog.BLOODHOUND
assert Dog.WEIMARANER >= Dog.BLOODHOUND
assert Cat.BRITISH < Cat.SCOTTISH
assert Cat.BRITISH <= Cat.SCOTTISH
assert Cat.BRITISH != Cat.SCOTTISH
assert Cat.BRITISH == Cat.BRITISH
assert Cat.SCOTTISH == Cat.SCOTTISH
assert Cat.SCOTTISH > Cat.BRITISH
assert Cat.SCOTTISH >= Cat.BRITISH
assert hash(Dog.BLOODHOUND) == hash(Dog.BLOODHOUND)
assert hash(Dog.WEIMARANER) == hash(Dog.WEIMARANER)
assert hash(Dog.BLOODHOUND) != hash(Dog.WEIMARANER)
assert hash(Dog.SAME) != hash(Cat.SAME)
# raise TypeError
Dog.SAME <= Cat.SAME
Dog.SAME < Cat.SAME
Dog.SAME > Cat.SAME
Dog.SAME >= Cat.SAME
Dog.SAME != Cat.SAME
The end of the story.
and use this Python ENUM insight for your well-codding!
Contributing
- Your contributions are always welcome!
- If you have any question, do not hesitate to contact me.
- If you would like to participate in the initiative Mojo🔥Driven Community, please contact me.
- Your help supporting this repository